Contents
- 1 ――薄ダイ・TSV・巨大パッケージが生む製造の極致
- 2 はじめに:GPUはもうただの「チップ」じゃない
- 3 1. HBMとは何か:「縦の超高層ビル」
- 4 2. 製造工程の「職人芸」ゾーン
- 5 2-1. DRAMウェハの薄化:髪の毛の直径より薄い世界
- 6 2-2. TSV:シリコンを貫く銅の柱
- 7 2-3. 積層とバンプ接続:「一枚でも死ぬとスタックごとNG」
- 8 2-4. ベースダイのロジック化:HBM4でさらに難しくなる
- 9 3. CoWoS:GPU+HBMをひとつにまとめる「最終組み立て」
- 10 3-1. CoWoSとは何か
- 11 3-2. なぜこれが「職人芸の極致」なのか
- 12 3-3. 熱設計:積層の呪い
- 13 4. 「自由に持ち運びして歩留まり落ちないの?」問題
- 14 5. まとめ:量産可能な工業芸術
――薄ダイ・TSV・巨大パッケージが生む製造の極致
スポンサーリンク
はじめに:GPUはもうただの「チップ」じゃない
AIデータセンターに積まれているGPUサーバを一台開けてみると、そこにあるのはただのシリコンチップ一枚ではない。GPU本体ダイを囲むように複数のHBM(High Bandwidth Memory)スタックが並び、それらが全部シリコンのインターポーザという「土台板」の上に密集して乗っている。この一体ものがさらにパッケージ基板に実装されて、初めて一つのAI用チップとして世に出る。
この構造を作るのがどれだけ難しいか。今日はそれを「工程の職人芸」という視点で解剖してみる。
1. HBMとは何か:「縦の超高層ビル」
まず基本から整理しておく。
従来のDRAMはマザーボード上のスロットに横並びで刺さり、GPUとは長い配線経由でデータをやりとりしていた。帯域幅には限界があり、GPUがいくら速く演算できても、データが間に合わないという「メモリウォール」問題が深刻化していた。
HBMはこの問題を、発想を変えて解決した。複数のDRAMダイを縦方向に積み上げてスタックを作り、そのスタックをGPUダイのすぐ隣に置く。配線距離を極限まで短くして、テラバイト毎秒クラスの超高帯域を実現する。
構造のイメージはこうだ。
| 要素 | 内容 |
|---|---|
| コアダイ(DRAMダイ) | 30〜50µmまで薄化した単層DRAM。8〜16枚を積層する |
| TSV(シリコン貫通電極) | ダイを縦方向に貫く銅の柱。層間データの高速通路 |
| マイクロバンプ | 各ダイ間の接続点。ピッチは数十µm |
| ベースダイ(ロジックダイ) | スタック最下層。I/O制御を担う。HBM4からはロジックプロセス活用が進む |
| 1スタックの帯域幅 | HBM3Eで約1TB/s、HBM4ではさらに上がる方向 |
HBM3Eで12層、HBM4では16層まで積層が進み、1スタックあたりの容量もどんどん増えている。「縦の超高層ビル」と言われる所以だ。
スポンサーリンク
2. 製造工程の「職人芸」ゾーン
2-1. DRAMウェハの薄化:髪の毛の直径より薄い世界
HBMスタックを作るには、まずウェハ上のDRAMをとにかく薄くしなければならない。
通常のウェハ厚から、TSVが露出するレベルまで削り込むには、バックグラインドやCMPなど複数の工程を組み合わせて、数十µmレベルまで薄化する必要がある。髪の毛の直径より薄いくらいの世界だ。
ここで難しいのは、ただ薄くするだけではダメなことだ。薄くした瞬間に反りやすくなり、割れやすくなり、次工程でのハンドリング難度が一気に上がる。つまり「削れば終わり」ではなく、「削ったあとに壊さず次へ渡す」ことまで含めて職人芸になる。
2-2. TSV:シリコンを貫く銅の柱
HBMの肝はTSVだ。シリコン内部に微細な穴を掘り、その中を銅で埋めて、上のダイと下のダイを縦方向につなぐ。
工程としては、穴あけ、絶縁膜形成、シード層形成、銅充填、研磨、そして薄化という流れになる。どの工程も難しいが、特に怖いのは、微細な欠陥が最後まで潜伏してしまうことだ。小さな空隙や応力集中が後工程で不良として出てくる。
つまりTSVは、見た目にはただの「縦配線」でも、実際には材料、加工、電気、熱が全部絡む総合格闘技みたいな存在だ。
2-3. 積層とバンプ接続:「一枚でも死ぬとスタックごとNG」
薄化してTSVを入れたダイを、今度はマイクロバンプで一枚ずつ積み重ねていく。ここが、歩留まりに最も直撃する工程だ。
感覚的には、トランプを12枚、16枚と積み上げるのに近い。ただし実物はトランプよりはるかに薄く、熱にも応力にも弱く、しかも全層で電気的に完全接続されていなければならない。
厄介なのは、1枚でも不良があればスタック全体が死ぬことだ。各ダイ単体の歩留まりが高くても、積層数が増えるほど全体の良品率は落ちていく。だからメーカーは積む前に良品ダイだけを厳選し、Known Good Die 管理を徹底する。
このへんから、もはや普通の量産工場というより、壊れやすい工芸品を何百万個も同じ品質で積み上げる世界に入ってくる。
2-4. ベースダイのロジック化:HBM4でさらに難しくなる
HBM3Eまでは、スタック最下層のベースダイもDRAM寄りの作り方だった。ところがHBM4からはI/O数が増え、制御が複雑になり、ベースダイをロジックプロセスで作る方向に変わってきている。
これは地味に大きい変化だ。つまりHBM1スタックの中に、「メモリプロセスで作る部分」と「ロジックプロセスで作る部分」が混在するようになる。
結果として、HBMは単なる積層メモリではなく、「DRAMメーカー」と「ロジックファウンドリ」が共同で作る複合製品に近づいていく。構造が高度になるぶん、芸術作品感はさらに増す。
3. CoWoS:GPU+HBMをひとつにまとめる「最終組み立て」
3-1. CoWoSとは何か
HBMスタックが完成しても、それだけでは使えない。GPUダイと物理的に接続して初めてAI用チップになる。この最終工程がCoWoSのような先端パッケージだ。
構造としては、シリコンインターポーザの上に巨大GPUダイと複数のHBMスタックを並べて載せ、それを一つの巨大パッケージとして仕上げる。GPUとHBMをシリコン上で超高密度に接続することで、従来では不可能だった帯域幅を実現する。
要するに、HBMは「積層メモリ単体」だけでは成立しない。GPUの隣に超短距離で置き、かつそれをまとめて高精度に実装するパッケージ技術まで含めて初めて価値が出る。
3-2. なぜこれが「職人芸の極致」なのか
CoWoSパッケージには、難しい要素が全部乗っている。
| 難しさ | 内容 |
|---|---|
| 大面積GPUダイ | 巨大ダイはそれだけで歩留まりが厳しい |
| HBMスタック複数 | 各スタックの歩留まり損失が累積する |
| 超高密度インターポーザ配線 | 信号本数も電源配線も膨大 |
| 実装精度 | GPUとHBMの位置ズレが許されない |
| 熱設計 | GPUとHBMの熱が一か所に集中する |
| 一発勝負 | 後から直しにくく、不良時の損失が大きい |
つまり、単体でも難しいGPU、大変なHBMスタック、さらにシリコンインターポーザ実装を全部まとめて一発で成功させなければならない。
全体の歩留まりを感覚的に書けば、
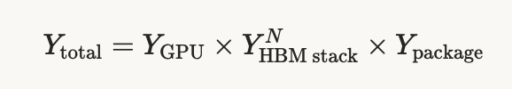
という掛け算になる。GPUが難しい、HBMスタックも難しい、最後のパッケージも難しい。だから総合歩留まりは想像以上に下がる。
これが、HBM付きGPUが高価で、しかも簡単には増産できない理由の中核だ。
3-3. 熱設計:積層の呪い
積めば積むほど帯域と容量は上がる。しかし積めば積むほど、熱の逃げ場がなくなる。
HBM3Eでは12層、HBM4では16層へと進み、しかもベースダイ側にロジック機能まで入ってくる。つまりスタック内の発熱分布はどんどん複雑になる。
発熱で反りが出れば接続不良、応力でクラックが入れば信頼性が落ちる。熱をどう逃がすか、どこに応力が集中するか、材料をどう選ぶか。全部が一体で決まる。
このあたりまで来ると、半導体設計というより、熱と材料と構造を同時に成立させる総合アートに近い。
4. 「自由に持ち運びして歩留まり落ちないの?」問題
MicronやSK hynixが作ったHBMスタックを、最終的な先端パッケージ工程に持ち込んでGPUと組み上げる、という意味での「工場間の移動」は実際にある。
ただし、これは決して自由な持ち運びではない。薄化済みダイや途中状態のスタックは、機械的ストレスにも温湿度変化にも弱い。扱いを間違えれば、それだけで反りやクラックや接続不良の原因になる。
つまり、「自由に運んでも大丈夫」なのではなく、「運び方まで含めて歩留まり設計している」が正しい。ここもまた工業製品というより工芸品に近い感覚だ。
5. まとめ:量産可能な工業芸術
HBM付きGPU一個を完成させるためには、
- DRAMウェハを髪の毛より薄いレベルまで削る
- TSVを形成して縦配線を作る
- 良品ダイだけを選んで多層積層する
- 必要に応じてロジックベースダイを組み合わせる
- 巨大GPUと複数HBMを先端パッケージで一体化する
- 熱、信号、機械的信頼性を全部同時に成立させる
という工程を経て、初めて一個の製品になる。
これを毎月、大量に、しかも歩留まりを管理しながら出荷しているのが今のAIインフラの裏側だ。DRAMやHBMが不足している理由も、簡単には増産できない理由も、この製造難易度を見ればかなり腑に落ちる。
結局、AI時代のボトルネックはアルゴリズムだけではない。極限まで薄くしたシリコンを、壊さず、ズレさせず、熱に耐えさせながら量産する。この「量産可能な工業芸術」こそが、AI計算資源の土台になっている。